Part three of a series on artificial intelligence.
My earlier posts on this topic dealt with some fairly sophisticated text-generation AI’s from the present and (likely) near future. But most of the AI you experience is very mundane, and often slips under your radar. AI is more ubiquitous than you may hope… and significantly stupider than you may fear.
So goes the thesis of Janelle Shane‘s newish book, You Look Like A Thing And I Love You: How Artificial Intelligence Works And Why It’s Making The World A Weirder Place. It’s an easy-to-read, fun introduction to what AI is, what it is not, how it works, and how it doesn’t. And it has very cute illustrations. Here is a brief introduction to some of the concepts in the book, told much less accessibly than Shane does, alas. Please bear with me for a moment.
What we call AI is many different things doing different tasks in different ways. Much of the time you hear about AI, it’s about deep learning. What is deep learning? It’s actually just a highly lucrative rebranding of multilayer perceptron neural networks, which have been around in one form or another since the 1960’s. What is a perceptron? Inspired by neurons, perceptrons convert a series of inputs to a single output via a weighting function. Let’s imagine a shape-classification perceptron with inputs like ‘number of corners’, ‘ circumference:area ratio’, and for some reason ‘color’. This would begin with random weights–let’s say it thinks ‘number of corners’ is very very important. But each time it calls a diamond a square, the weights are adjusted, just a little, so that it will be less wrong in the future (or so we hope). Where can this go wrong? Let’s say that the data this perceptron is trained on contains a lot of shapes from playing cards. It would end up learning that color was highly predictive. In the future, when you showed it a red circle, it would probably tell you it was a heart!
A multilayer perceptron is simply when perceptrons feed into each other. So the next one in the chain would consider the output of our ‘which shape?’ perceptron, alongside other data, when performing its own task. You can probably see how this compounds errors in odd ways. Most of the time an individual perceptron’s rules are ineffable, so these things can be rather hard to debug.
Take the example of Microsoft’s image-classification AI, Azure. It was very good at identifying pictures of sheep while it was being trained. But when it was put to the test, it identified any green pasture as a picture of a sheep! It also saw giraffes everywhere. It learned that ‘giraffe!’ was often a better answer than ‘I don’t know’, probably because there were a few too many pictures of giraffes in the training data. And if you asked it how many giraffes there were, it would give you a weirdly high number–because the training data didn’t have any pictures of individual giraffes. This stuff can get very weird, very fast. As Shane illustrates in her book,
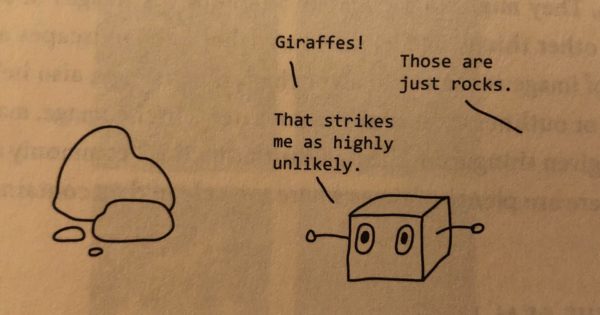
AI’s are also lazy, lazy cheaters–or rather, they optimize for exactly what you tell them to optimize for. One time, researchers wrote an evolutionary algorithm tasked with designing robots that could move, from a pile of parts. The training judged how good a robot was at moving by how quickly it could reach a goal at the other end of a virtual room. So the AI ended up making robots that were just big towers of parts, which then fell over in the direction of the goal. In another experiment, researchers asked an AI to design a circuit that could produce oscillating waves. The AI instead evolved a radio that picked up and reproduced oscillating waves from nearby computers.
Well don’t get mad–they did what you asked.
We all deal with AI’s every day, and surely we are encountering errors like this all the time, whether we can recognize them or not. And these errors can have significant repercussions. Let’s look at some examples of biased training data (like in the above hypothetical about playing cards). Facebook and Apple (and many, many others) have made facial-recognition algorithms that didn’t work on black people and/or women because the training data didn’t have very many of them. A self-driving Tesla that had never encountered a stopped perpendicular trailer thought it was a billboard, ignored it, and then crashed into it, killing the driver.
If you’d like to learn more stuff like this, along with many entertaining and illustrative examples (like telling an AI trained on Harry Potter fanfiction to write recipes), I highly recommend checking out this book! It’s great for everyone from beginners to semipros, and possibly beyond.
Miss Bianca
I just finished You Look Like a Thing and I loved it! Entertaining *and* informative – I mean, LOL funny, which is something I have sorely needed these past few months.
EthylEster
I would VERY strongly recommend Melanie Mitchell’s Artificial Intelligence to anyone who is really interested in learning about this technology. It doesn’t have very much math. It discusses the main recent AI application successes: voice to speech, image recognition, game playing (Deep Blue, chess, GO, Google Translate, etc).
I was already generally knowledgeable about AI (traditional expert system and early neural nets) but I kept reading about “recent breakthroughs” and wanted to know more. This book explains what changed 10 years ago to produce the current explosion in AI apps. It also discusses the involvement of big data and the web in the explosion. It is clearly written and the author obviously knows her stuff. She was a grad student of Hofstadter, Godel Escher Bach author.
The book is funny in places but also VERY scary to me (and, I think, also to the author).
Plus it talks about the Amazon Mechanical Turk worker!
Obvious Russian Troll
I perhaps unfairly blame AI and machine learning for making search and recommendations on Google, Youtube and Amazon so much shittier than they used to be.
MattF
I recall an AI lecture I went to, back in the 60’s– the speaker, brimming with energy and confidence, drew a big N on the blackboard, and then drew a box around it. “We start with Nature”, he said.
EthylEster
@Obvious Russian Troll: It’s a powerful tool that can be used for good or bad. More people need to understand how it works.
jl
Thanks very much for an important post. I’ve heard a saying among stats and predictive analytics people, which is ‘artificial intelligence is not as artificial as people think it is.’ Many of the study design and sampling issues, and problems of delicate and unpredictable estimation methods are common to AI, predictive data mining, predictive analytics, all that new fangled stuff, and plain old boring statistics. Which brings to mind another saying ‘there are lies, damned lies, and statistics’, and as a statistician, boy, do I know that one is useful to remember
Edit: one issue is that many of the same concepts are referred to by different jargon terms in the different AI fields, and in statistics. Once that is ironed out, many of the common problems can be identified, and an interdisciplinary team can work off the same page. Thankfully, I’ve never seen a fight about which field’s jargon is better. Probably because in terms of consistent and accurate nomenclature, everything from plain old boring stats to the newest fanciest AI, we stink compared to other sciences.
catclub
of course, this means that the AI in it allows it to hit things – even sturdy (billboard!) inanimate things – in the road, which no driver will intentionally do. A driver WILL hit a cardboard box, but that is about as far as real drivers will go. The general rule should start as “Don’t run into anything higher than a squirrel” (sorry squirrels)
Roger Moore
The problem with overfitting the training data is a really big one. Of course it’s not limited to artificial intelligence; plenty of the perceptual problems we encounter with human intelligence is a result of overfitting to an unrepresentative data set. But it’s a huge problem if we expect AI to avoid problems with human bias; if we train the AI on a biased data set produced by humans, it will wind up replicating rather than correcting that bias. IMO, this is the big lesson to remember when people start talking about replacing human judgment with AI; it only works if the AI is trained on really good data.
Major Major Major Major
@catclub: The part of the AI that does such things thought it was a billboard and completely ignored it as an input. A different, lower-level part of the AI eventually recognized it as an immediate obstacle, but it was too late to adequately brake.
It’s perhaps best to think of these big complicated AI’s as a swarm of smaller, stupider AI’s. (Shane discusses this in her book.)
trollhattan
IMO the left turn will continue to keep self-driving cars many Friedman Units away from reality.
An actual consumer product containing AI that you may purchase today is the Olympus E-M1X. It has three AI focus modes (“Intelligent subject detection”) for racecars and motorcycles, aircraft and trains. Am told that third one is there because Japanese are crazy about photographing trains. I’ve demo’d the camera in the car mode and it’s crazy-impressive.
Olympus hint they are developing more modes for adding to the camera via firmware update. If they ever add sports I might buy one.
EthylEster
@catclub: The general rule should start as…..
But there is no rule, general or specific. The car driving app was trained on a bunch of driving situations and it “learned” how to respond to various situations. Evidently it had never encountered the particular situation where it failed. It is very difficult (impossible) for humans to examine the driving model being used and conclude afterward WHY it did the “wrong” thing. The model is a black box. There are literally thousands (millions?) of weights in these deep learning models.
catclub
@Major Major Major Major: big complicated AI’s as a swarm of smaller, stupider AI’s.
and from reading GEB, the fascinating – and hardest part – of AI’s is figuring out when one answer gets to jump all the way up to top priority
EthylEster
@Roger Moore: it only works if the AI is trained on really good data.
Two comments. 1. A MASSIVE amount of data is required. 2. We don’t know how to recognize good data.
catclub
@EthylEster: so you go argue with major^4 about this: (that is what I meant by a general rule)
Major Major Major Major
We certainly know how to do a better job than we currently are, by for instance making the faces in your training set look like your user base, not your software engineers. Very basic stuff that many other disciplines are aware of and often quite good at!
Major Major Major Major
@catclub: We can examine some inputs and outputs (here’s a picture, it thinks it’s a billboard), but it’s usually hard to introspect the actual perceptrons to tell you how it arrived at that conclusion. But we can guess that being a stationary rectangle had something to do with it.
eemom
Someone, don’t know who, said we don’t need to fear that computers will someday become smart enough to control the world; we need to fear the fact that they’re stupid and already do.
That said, I co-wrote an article a couple of years ago about AI and insurance. Huge subject teeming with legal issues.
Roger Moore
@EthylEster:
Part of the problem is that these two imperatives can be at odds. What do you do if there isn’t enough top quality data to train your AI? Do you try to train on a data set that’s too small, or do you compromise on data quality to get more quantity? Nobody is going to be happy accepting that the answer may be to shelve the idea until you can either get a better data set or improve your training methodology to work with a smaller one.
Obvious Russian Troll
@EthylEster: Gotta agree with that. We’re going to see it applied in a lot of places where it doesn’t make sense, or where we don’t have the data to make it work properly.
We’re also going to see it push things that sell heavily in unrelated searches.
Baud
I’m still waiting for an AI toilet.
Yutsano
Sigh. You just want to trigger the Butlerian Jihad early don’t you?
Ben Cisco (onboard the Defiant)
OT note to Avalune and WaterGirl: Thank you for the sealion cake/chow. When I made the crack about the chow I never dreamed it would actually show up! Been away from the blog for a while, and today was the first time seeing them in real time.
MisterForkbeard
I’m buying a copy of this. It looks wonderfully entertaining and right in my wheelhouse.
Yutsano
@Ben Cisco (onboard the Defiant): I gave in and started using it on one commenter. I got Sea Lion Chow too! That’s just so brilliant.
Major Major Major Major
@Baud: This Smart Toilet Can Read Your Anus Like A Fingerprint
https://www.businessinsider.com/scientists-designed-a-smart-toilet-with-butt-recognition-technology-2020-4
Baud
@Major Major Major Major:
Finally! I’m so tired of strangers using my crapper!
Dorothy A. Winsor
@Major Major Major Major:
I so did not need to know that.
EthylEster
@catclub: The part of the AI that does such things thought it was a billboard and completely ignored it
Uh, there is no thought. There is no ignoring. There is a deep neural net (or a series of them) that have a zillion weights that are applied to an input vector that is generated from the sensors in the car.
I’m not trying to be a pain in the ass here. It’s not like a decision tree where at some point “if object bigger than x, do this” is decided. That kind of AI (like an expert system) is old and effective for some situations but could never tackle really complex tasks like image recognition. But at least we humans could understand how it works. Deep learning? Not so much. And that is at the core of the scariness.
Nora Lenderbee
@Major Major Major Major: So our anus-prints will be on file with Homeland Security now? Will these toilets be installed in airports to catch terrorist butts?
Ben Cisco (onboard the Defiant)
@Yutsano: When I saw it I had to stifle a laugh – pulled a huge lower back muscle that doesn’t need the workout just now. It’s cool feeling like I inspired a small contribution to the blog!
EthylEster
@Roger Moore: What do you do if there isn’t enough top quality data to train your AI?
Exactly. IMO this is the problem with a lot of the spectacular failures. Not enough data? Just crank the computational engine anyway. Then later someone comes along and says: This is crap. It may be too late by then.
Eric U.
The real problem with “AI” is that CEOs have been sold on it and they aren’t very smart. The Tesla crash is a good example. Musk is a very stupid person with a lot of money and he doesn’t want to put expensive sensors in his cars. Cameras are inadequate for the task. But combine them with “AI” and you can convince yourself differently.
Major Major Major Major
@EthylEster: I also say viruses can ‘live’ on surfaces for x amount of time. I like using terms people will understand without having to give a crash course on Searle
I’m also not so vain as to believe computers cannot think—though it’s not a term I would use in a philosophy paper for a 2018-era car.
Miss Bianca
@EthylEster: Well, now I have to look for one, too – once the library is open and I can take back the Shane book!
EthylEster
@Major Major Major Major: We certainly know how to do a better job than we currently are.
Yes, and as more people get more informed about the tech, we will have a chance to improve. Kearns and Roth in “The Ethical Algorithm” address this aspect of AI. However, as you mention, it means paying attention to the quality of the training data.
And in data-starved scenarios it is hard (impossible?) to find enough “good” data. So even if “we” know what should be done, it will not always be done in corporate and government projects. That’s why your posting this here is excellent. THIS topic is important.
Miss Bianca
@Eric U.: The point that Shane’s book makes about that situation with the self-driving Tesla is that yes, indeed, you still need a human driver, in addition to the AI. The problem seems to be that around 95% of the time, or maybe even more, you can rely on the AI to handle most routine driving situations. But the least sign of something weird that it hasn’t been trained to handle – but which a human can instantly perceive to be a threat and respond to – the human has to be able to jump in and take control. Not easy to do if, say, you’re sleeping in your AI-driven car at the time.
Roger Moore
@EthylEster:
I guess the other, possibly more important, question is how you know you have enough data. I’m sure plenty of AI developers have discovered the weaknesses in their training data only after releasing it and discovering problems with data outside their original set.
JaneE
In my day there was a joke about the computer who dunned a customer for a zero balance until he wrote a zero dollars and zero cents check to clear it. We blamed the programmer for that. It looks like the new AI systems can learn to be stupid all by themselves. I will still blame humans involved.
Amir Khalid
@Major Major Major Major:
Wonderful. We can now look forward to identification documents bearing our ass-print.
Roger Moore
@JaneE:
Part of the problem with all this stuff is that a system can get so complicated a single programmer can no longer understand the whole thing, only the part they’re working on. That can put an interaction between parts deep within separate subsystems into a place where nobody can fully comprehend it. That doesn’t absolve the programmers, but it suggests there may be limits to the size of programs we can develop and hope to keep reasonably bug free.
That said, the basic point of the AI we’re talking about here is to bypass the whole issue by not requiring the programmers to understand how the system works. There’s some kind of general purpose AI engine, but the guts of how the particular system works is down to the weights assigned to the system by training it, and those are essentially opaque. You can get some really interesting results, but at the cost of not being able to get any kind of deep understanding of how the system works.
JustRuss
Seems like maybe letting AI control cars on public roads might be a bad idea. But hey, gotta break a few eggs, right?
Major Major Major Major
Two lines
trollhattan
@JustRuss:
Have a hunch self-driving semis on interstates will happen sooner than passenger cars, and wouldn’t that be fun?
PenAndKey
As someone who has, without shame, read hundreds of Harry Potter fanfiction stories of various quality I’ll admit, I’d pick up the book for that bit alone. That sounds… hilariously angsty and bad.
Also? If you wade through the fanfiction websites long enough you quickly learn how to spot the tropes and avoid the bad ones. Some of the best stories I have ever read have been written by fan writers as either pure in-world stories or as crossovers with other IP (my favorites are Mass Effect, Star Wars, and the Thor/MCU worlds). BUT for every good book I find I start and drop at least a dozen bad ones. I would absolutely love to see what an AI would make of that type of source
@trollhattan: If it means I won’t have to worry about road raging drivers riding my ass so close in the right lane that I legitimately worry about them hitting me and running me off the road I’m okay with that. I drive on the interstate a lot and that’s happened to me four times in ten years. It’s a small number, but even once it too often.
EthylEster
@Roger Moore: question is how you know you have enough data
Yes, but that is a problem with all models. They have to be validated. They have to be tested “to destruction” and that’s boring and labor intensive. And nobody is making money until the model is deployed.
I don’t think there is a way to ever know for sure when enough of the correct data has been supplied in a deep learning model. Which is another aspect of AI that is worrying. You have to keep tracking performance and asking if that is “good enough”. And when death is one of the possible outcomes, how to decide “good enough”?
EthylEster
@JaneE: I will still blame humans involved.
As you should.
There would be no artificial intelligence without human intelligence.
Also the deep learning networks have to be configured, which has given rise to a group of “wizards” who know how to configure them or can convince someone they know how. ;=) The networks are not parameterless. So humans are involved from the beginning. And humans usually decide which data are used.
RSA
@JustRuss:
There are obvious ethical considerations. Unfortunately, we’re putting the relevant ethical decisions in the hands of software people and businesspeople, two groups that have not demonstrated above-average talent in meeting such challenges. (I’m over-generalizing, of course.)
Calouste
@Major Major Major Major: Only as long as one of those two lines is a comment.
Major Major Major Major
@Calouste: idk there are magic comments in some languages & frameworks
Feathers
Having worked supporting a research group in the field, I have some thoughts.
Major Major Major Major
@Feathers: There was an AI that developers intended to detect cancerous growths. It ended up detecting rulers, since they were included in most of the training images of cancerous growths.
RSA
@Feathers:
This is the way things work in some areas of the aerospace industry and car industry (e.g. with crash testing). But with autonomous vehicles, public and regulatory oversight is almost entirely missing, except at the level of state and local governments giving companies approval to test out their work on public roads.
This leads to some bullshit situations that are touted as advantages when they’re really, really dangerous. Tesla, for example, brags that they can send out software updates overnight, without the owners of their cars even having to know. Gee, I hope their software engineers never make mistakes! I hope they’re never hacked! I hope no completely and easily foreseeable problems arise!
JaneE
@Roger Moore: They have been using programs to write programs for more than a half century (RPG, e.g.) and while things have become more sophisticated and “user friendly” we haven’t really figured out how to get bug-free or mistake-proof systems out for public consumption. I love all the new technology and wouldn’t want to do without any of my modern tech, but I still think that just because computers make something possible doesn’t mean that it is beneficial. I sometimes wonder if the Garden of Eden wasn’t the brainchild of some poor early agriculturalist longing for the days of hunting and gathering. If nothing else, the Covid crisis has shown just how incapable we are of supporting ourselves without a whole society of technology and specialists and we just keep moving farther and farther in that direction. AI is just one area where we keep generating more things that only a few can really understand but everyone can (mis)use. Tesla calling their system autopilot is the example that comes to mind.
Brachiator
Interesting conversation. Another book recommendation for my “buy” pile.
Misterpuff
@Nora Lenderbee: Know your enemy’s anus./ HHS Recruiting Poster
RSA
Have you ever come across Karl Sims’s work from the mid-1990s? I used to show students this video on Evolved Virtual Creatures, which though ancient is still informative and entertaining.
glc
I’m just going to go with the idea that if I can’t tell what’s in a picture, it’s probably a giraffe.
I find that oddly compelling. (But maybe just one giraffe, I have my own training set.)
Major Major Major Major
@RSA: I have not I’ll have to take a look!
Martin
I would dispute this description a bit. Feathers is correct that there’s a lot of bad AI out there. I don’t agree with M^4 that AI is lazy. It’s just kind of dumb. If you tell a bad employee to move these boxes of china from here to there and they *throw* them, because that’s most efficient, then they’re doing what you asked, and doing it quickly. That’s AI. You assumed a certain degree of common sense that you also want them unbroken, but you didn’t specify that. So the robot that falls over as a form of locomotion is simply meeting the goal. Had you specified *sustained* movement, it wouldn’t do that.
Bad AI is the perfect embodiment of Goodhart’s Law
But that’s not a failing of the AI, it’s a failing of the programmer for not understanding Goodhart’s Law. I can point to countless meatspace policies that reflect the same lack of understanding (if increased GDP is the target, then employment will suffer as employment and GDP are increasingly in opposition to each other).
But this critique also fails to account for the success of AlphaGo Zero and OpenAI Five. These are legitimate advancements in machine learning in that they exceed the abilities of the best humans at non-trivial activities. AlphaGo Zero starts with just the rules of the game and within 3 days can beat any human. What’s more, the same code can do the same thing with other games – chess, etc. It just needs to be given the new rules.
OpenAI Five is very different. It’s not focused on that ground up learning. But it’s playing a game that is complex in ways that Go is not, not the least of which is that it’s five AIs playing five different heroes against five humans playing 5 yet different heroes. It is asymmetric where Go is symmetric, and where Go is a perfect knowledge game – each player can see the entire board, Dota is not – lots of things are happening that the players and AI cannot see. But it does require the AIs coordinate, and adapt to an ever changing landscape as Dota involves heroes upgrading, buying items, objectives being taken which changes how the playing field works, and so on. Again, highly non trivial.
In both cases, the AIs have changed how humans play the game, not against the AI but against each other because the AIs have exposed limitations in how the humans settled on optimal strategy.
And there are very good practical implementations as well. Being able to deposit a check using a photo is purely a function of machine learning conquering a simplified handwriting space. It’s not perfect, some checks do have to go to humans for evaluation, but it’s successful enough that virtually everyone offers this service now.
What this tells us is that the hardware and some of the frameworks are up to solving either superhuman problems or fairly simple analog problems with accuracy that at least matches humans, but it’s gated behind programmers, like policy makers, needing to be very good at what they do. The flip side of this is that it exposes these tools to people like me to solve problems in our narrow areas of expertise.
The project I’m working on now regarding reopening is sufficiently complex that it would not be possible to get campus staff to implement it in the time window we have available at the necessary level. Pandemics are stochastic. It’s not about preventing specific people from getting the virus, but preventing enough of them from getting it that it spreads slower than the rate of infection. That’s the reopening problem – how do you engineer things to keep us below that line. The solution thankfully need not be perfect, because human behavior doesn’t allow for that, but if the problem is complex enough, human workers, particularly when you need to parallelize the solution and run into the complexities and speed of human communication, are likely to fall short of that line. But I can use deep learning to crank away at solutions 24/7 until it finds solutions that put us below that line. It has narrow benefits, but it cannot be done any other way right now. That’s really what the lockdown is about, an admission that policy makers don’t have a better remedy or a means to develop one. One benefit of a college campus is that we have sufficient control to give some other ideas a run. Essentially, what if every time you went to the grocery store, you were there with exactly the same other customers every time. For one, your first order exposure is now limited to just those people, and if one of you tests positive, the contact tracing at least of the grocery store is already done. We know exactly who to test and/or isolate and can implement it immediately.
I don’t know if there is a configuration that gets us under the line, but the machine learning will tell me whether it’s possible or not, and if it is possible, will give me one or more solutions to the problem. Without it, we’d either need to trust that it’s not possible, or reopen and deal with the problem as we go. Now, will I trust that I built the system correctly? No, but I can feed the results into a different tool that can confirm the result.
Brachiator
@Martin:
A very interesting and useful example.
The employee is not bad, he or she is malicious. He knows from the social context of meaning that “move” means to move the boxes intact and without damaging anything.
The robot is not malicious and the trick is how to sufficiently provide all of the context that a human being understands about what “move” means.
RSA
@Martin:
Cool, thanks for the example from your work!
For what it’s worth, I agree with how you characterize the weakness of AI: these are remarkably capable systems, given how dumb they are.
At a recent workshop on speech and robotics, one of the natural language researchers mentioned a nice ambiguity that I’d never noticed before. (We were at dinner in a restaurant after the technical talks.) The average person will have no problem interpreting the command, “Go through the front door,” but what if it’s a military robot? You want it–at least sometimes–to stop, turn the door handle, open the door, and go through the now-unobstructed doorway. But there’s an alternative Kool-Aid Man way to execute the task that the robot may have in its repertoire. It’s hard to design robots that do the right thing if we’re not always aware of even the existence of a wrong way to do something.
Martin
@Brachiator: Employee may not even be malicious, may just be ignorant. As the task gets more complex, that becomes more common to the point where at some point every employee is ignorant of some aspect of how to do the task correctly without a lot of explicit training.
Most of my career has been solving really complex problems that require a team to address. They scale poorly – the larger they get, the larger the team, the more coordination and communication, until they consume all available time. Classic mythical man month problem. So we build tools to automate the mundane stuff, but then the staff are tacking increasingly complex aspects of the problem which means they need more and more training because the constraints get more and more subtle and easy for people to miss. They aren’t malicious when they keep you in class for 5 hours with no break for a meal, it was variable #7 in the problem and they simply couldn’t account for it. It was beyond what a team of humans could do in the timeframe given them, or, ‘make sure every one of these 45,000 people has time for a meal in their schedule’ wasn’t a target and nobody considered it – they were ignorant of that need. Chance are, we knew it should be a target, but it was simply beyond our capacity to meet it so we never bothered to train people to consider it.
We’ve grown to the point that we can really only adequately solve the problem through machine learning. How do you let 35,000 students complete their degrees while interacting with the fewest people possible is not a problem we’re trained to solve, nor can I hand that to a team of even really good employees and get a solution to it. A problem with that many degrees of freedom is just too big. I can’t even program an empirical solution to it. But I can program a stochastic solution. Teach the computer what the targets are, let it figure out for itself what the dead-end configurations look like, and let it grind away at millions or hundreds of millions of implementations and come back with ‘this is roughly the best you can expect to get’. And then we can look at that and decide if that’s acceptable or not. If we’re close, we will likely tweak the targets a bit here and there and then roll with the solution it gives us. It takes autonomy from students, which they won’t like, but it would bring them back to campus. That’s the trade-off.
RSA
@Brachiator:
This is harder than it might sound. For an example, not too long ago Ernest Davis published a paper called “How does a box work? A study in the qualitative dynamics of solid objects,” which takes close to 70 dense pages to formalize in logic the task of “using a box to carry a collection of objects from one place to another,” and being confident that a plan will succeed. It’s not my style of AI, but Davis has argued that there are no stronger candidates for handling qualitative reasoning.
Martin
@RSA: Exactly. Technical writing is the art of understanding what we assume people understand, and then dropping that assumption. That’s also where philosophy comes into play here. How does an autonomous car deal with the trolley problem? The answer is that if you stepped the problem back far enough the machine wouldn’t design a trolley that didn’t have a failsafe. It would simply avoid the trolley problem entirely. (‘Design a good trolley’ is always the correct answer, btw, because the failure came in the design phase, not in the scenario presented to you).
So, it begs the question – should we rely on natural language to solve that problem? The answer is generally ‘no’. Disciplines have specialized language for that reason. The military would say to ‘breach’ the door, to communicate their intent more clearly vs ‘go through’ the door. Further, the military has gone to lengths to choose their specialized language to reduce confusion due to homonyms. That’s why the NATO phonetic alphabet exists, and governs the command you holler to fire control over a radio while you’re being depth-charged or whatever that sounds distinctly different from any other command you might holler at them, so there is no confusion in all of that chaos.
One of the other benefits that comes out of AI is contextualization. Traditional programming tends to be very poor at carrying context as a formal element that can be acted on. But context is critical to how natural language functions. ‘Get me a pen’. ‘Oh, make it a blue one’. If you don’t carry the context of the pen, the clarification of ‘blue’ makes no sense. Traditional programming would give you one.The guy at fire control while being depth charged knows the context of the command. He’s experiencing it first hand. He knows ‘shoot at things’ is a more likely command than ‘get me tea’ in that context. Computers aren’t inherently bad at this, but how we program computers is. Machine learning is finally starting to address that shortcoming, which is a shortcoming of human-made computer languages and practices.
So, to be clear, I’m very pessimistic on computer science being a good major for people, simply because I don’t think we get good outcomes from CS folks learning how to be domain experts, rather we get good outcomes from domain experts learning how to apply CS. CS is an important discipline that everyone, at least everyone with a policy role, needs to know. Your code is your policy, and you need to consider who is really setting your policy – you, or the folks that you contracted to write the system? (It’s always the latter, btw).
Captain C
@Major Major Major Major: No. Just, no.
(Albeit strangely and horrifyingly interesting.)
Feathers
Reminded of a summer day camp where I worked as a teen, back in the 80s. There were computer classes. One of the kids came back to our homeroom saying he hated it. “The computers are so stupid. You have to tell them everything.” Truer truth never spoken.
On a more BJ note, I was playing with my sister’s rescue pup. I grabbed a stick and tossed it for her to fetch. I’m terrible at throwing. So the pup came running back to pick up the stick, then turned around to run with it to the far end of the yard. She was so happy with herself. Surely that was my intention! I laughed my ass off and took her inside for some of the very fancy dog treats I had bought her at the farmer’s market.
Brachiator
@Martin:
The example of moving a box of china is not a task of increasing complexity. If I bring a package to the post office marked “fragile” or “handle with care,” I will presume that a competently trained employee is not going to throw it or kick it. There is a reasonableness standard at work here. And even here, we would have to investigate why the employee was a “bad employee.”
And even with tasks of increasing complexity, some people will use ingenuity to come up with solutions, while others may need to stop, ask questions or get additional training. Could this be applied to AI as well, a recognition that more training is needed?
I have seen robots trained to pick up and move an egg without breaking it. I have no idea how this is done, but I suppose that it is a totally separate process from the way that a human being learns to pick up and egg, and then apply that learning to similar objects. Is the trick, then, to program whatever observable result would be the equivalent of human beings picking up and transporting eggs or similar objects without breaking them.
In Japan (but not so much here, yet) engineers are developing social robots who can pick up and carry elderly nursing home patients without harming them in any way. Interesting programming challenge.
And I can imagine that the work that you do that affects hundreds (thousands?) of students involves incredibly complex decisions.
EthylEster
@Martin wrote: ‘Get me a pen’. ‘Oh, make it a blue one’. If you don’t carry the context of the pen, the clarification of ‘blue’ makes no sense. Traditional programming would give you one.
Google translate is excellent on single words, very good on simple sentences, and not so hot on paragraphs. Much of this is due to the sentence being the training unit. So the translator works on each sentence sequentially. Thus, no carryover about context from a previous sentence. I don’t know how they will ever get past this.
It seems to me that AI can be very impressive in learning narrow, focused tasks, like speech recognition. But driving is NOT a narrow task. Yet a kid can learn to drive fairly quickly. Not surprisingly humans really are good at doing things humans value.
Feathers
@Brachiator: But “more training” means the robot cannot do the task then, a person must stop whatever the production line is doing and find some other way to move the box. The “training” of the AI means going back to the computers, which takes time and an enormous amount of processing power (five figures for a grad student paper project). We talk about the climate implications of the computer processing used for bitcoin, but AI is a similar drain.
No One of Consequence
Countdown to Butlerian Jihad in
3…
2…
1…
Peace,
– NOoC
RSA
@Martin: All good points.
Feathers
@Brachiator: The robot carrying the human is something like a 500th generation project. You can’t start with carry a nursing home patient. You start with one robot that moves and another that picks up a box.
One of the real tricky bits is HCI – Human Computer Interaction. How do you have the robot introduce themselves to the person they are going to carry? How do you have the car let the person know that they have to take over and drive now?
Another interesting bit of self driving car problem is that they require very clearly marked roads. Largely able to be handled on the interstates, but who will pay for upgrading our city streets? Some see it as a chance to build out pedestrian safe crosswalks and separated bike traffic lanes.
And, yes, I believe that self driving cars should be required to save pedestrians and other drivers rather than their own passengers. Why? Because it will cause companies to think about this things a lot more clearly. And they all need to be electric.
RSA
@EthylEster:
This is a good example of the subtlety of natural language, something I’ve learned about recently, talking with a linguist.
One sense of “make” is a clarification, as in the sentence above. There’s another sense in which that sentence asks the impossible. If I’m bringing you a pen, I can’t make it a color that it is not already.
(A related example that I’ve come across is the difference between baking a cake and baking a potato. I first thought, “What? ‘bake’ is the same in both cases!” But no–if you ask about the existence of the thing before you started baking, the potato did exist but the cake did not.)
In any case, one problem is that the AI system may simply not understand what’s being said. This used to happen on Star Trek with Spock and Data all the time, but the writers only touched the surface.
Brachiator
@RSA:
RE: The robot is not malicious and the trick is how to sufficiently provide all of the context that a human being understands about what “move” means.
Oh, yeah, I imagine it must be.
@Martin:
This gets very interesting. I have nerd friends who absolutely believe that the ethical “solutions” in science fiction will be applied to the real world, and should also be accepted as “rules” applying to other fiction. So I once got into an unnecessarily heated argument with a co-worker who panned a movie with killer robots because he presumes that Asimov’s Law, that robots will not harm or cause harm to come to a human, was not respected.
But here is how I might want this to be applied to autonomous vehicles. If I were driving a car and there was a sudden swerve and I had to decide whether to plow into a bunch of innocent people or run the car off the road and possibly kill myself, I might decide to sacrifice myself. However, if I were a passenger in an autonomous vehicle, I would strongly prefer that the default decision would always be to try to save me first.
On top of this, if accident avoidance protocols could be programmed into vehicles, would auto manufacturers be required, for insurance and liabilities purposes, consider and factor in who might be allowed to die in certain circumstances?
Bill Arnold
@EthylEster:
The Deepmind AlphaZero[1] work and related/inspired by explorations since then are scary interesting. Reinforcement learning in general is interesting. (IMO.) As are Monte Carlo tree search and related techniques. (I need to poke at the literature again; been a while.)
[1] Self-service piece, but interesting: AlphaZero: Shedding new light on chess, shogi, and Go (06 Dec 2018)
and their paper:
A general reinforcement learning algorithm that masters chess, shogi and Go through self-play
Bill Arnold
Humans aren’t actually very good at driving. They’re OK, and professionals like truck drivers tend to be better, at least the older ones.
AI drivers just need to do significantly better than human drivers to be a utililitarian sort of improvement. (Ignoring the quality of life difference between driver time and passenger time.) Lawyers and a general legal framework to handle fault could be a larger issue. (An individual driver is a limited-resource legal target; a large corporation, larger.) (And don’t get me started on trolley problems as real-time negotiation problems. Lot’s of negotiation can be done in a few 10s of milliseconds and low latency communications.)
Rates of Motor Vehicle Crashes, Injuries and Deaths in Relation to Driver Age, United States, 2014-2015 (June 2017)
About 1 per 30000K miles for the safest age cohort, 60-69 year olds, significantly worse for other cohorts.
There’s something to be said for paying attention 100 percent of the time.
slightly_peeved
The thing with autonomous vehicle trolley problems is that you can take all the research money on reliably incorporating moral decision-making into your autonomous vehicle, spend it on better brakes and seatbelts, and get a far better result.
A lot of the big advances in autonomous robotics don’t track with new algorithms, or new approaches to AI, as well as they track with improvements in sensing technology. Using deep learning to detect objects in front of a vehicle is never going to have the reliability of lidar. Tesla just want to do it cheaply.
Brachiator
@Bill Arnold:
Which almost no one does.
Apart from the people who insist that they can have long conversations on their phones while driving, I’ve seen people put on make-up, brush their hair, change clothes, eat breakfast and even read books while driving.
A friend was a sales rep, and I noticed that he never got angry and rarely drove over the speed limit. On avoiding road rage arguments with other drivers, he simply noted that he was on the road too much to get worn down over petty driver nonsense.
Eolirin
@Brachiator: The AI does. I think that’s the point.